
Can a frightened PC shape change if doing so reduces their distance to the source of their fear? How is glue used to load data into redshift? If you've got a moment, please tell us what we did right so we can do more of it. You have successfully loaded the data which started from S3 bucket into Redshift through the glue crawlers. You can query the Parquet les from Athena. I could move only few tables. 2. The AWS Glue job can be a Python shell or PySpark to load the data by upserting the data, followed by a complete refresh. 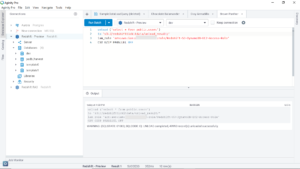 Working knowledge of Scripting languages like Python. For the processed (converted to Parquet format) files, create a similar structure; for example, s3://source-processed-bucket/date/hour. Copy JSON, CSV, or other There are several ways to load data into Amazon Redshift. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface. CSV in this case. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. 2. Year, Institutional_sector_name, Institutional_sector_code, Descriptor, Asset_liability_code, Create a new cluster in Redshift.
Working knowledge of Scripting languages like Python. For the processed (converted to Parquet format) files, create a similar structure; for example, s3://source-processed-bucket/date/hour. Copy JSON, CSV, or other There are several ways to load data into Amazon Redshift. Users such as Data Analysts and Data Scientists can use AWS Glue DataBrew to clean and normalize data without writing code using an interactive, point-and-click visual interface. CSV in this case. In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. 2. Year, Institutional_sector_name, Institutional_sector_code, Descriptor, Asset_liability_code, Create a new cluster in Redshift. 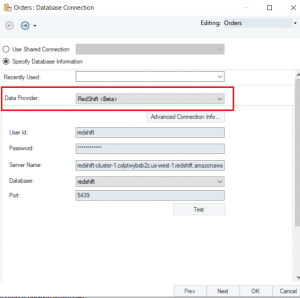
 more information Accept. create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30)); Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue.
more information Accept. create table dev.public.tgttable( YEAR BIGINT, Institutional_sector_name varchar(30), Institutional_sector_name varchar(30), Discriptor varchar(30), SNOstrans varchar(30), Asset_liability_code varchar(30),Status varchar(30), Values varchar(30)); Created a new role AWSGluerole with the following policies in order to provide the access to Redshift from Glue. To learn more about interactive sessions, refer to Job development (interactive sessions), and start exploring a whole new development experience with AWS Glue. Give it the permission AmazonS3ReadOnlyAccess. You can also access the external tables dened in Athena through the AWS Glue Data Catalog. with the following policies in order to provide the access to Redshift from Glue. Amazon Redshift is a fully managed Cloud Data Warehouse service with petabyte-scale storage that is a major part of the AWS cloud platform. CSV in this case. Asking for help, clarification, or responding to other answers. A default database is also created with the cluster. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. In the query editor, run the following DDL command to create a table named, Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key. With this solution, you can limit the occasions where human actors can access sensitive data stored in plain text on the data warehouse. Column-level encryption provides an additional layer of security to protect your sensitive data throughout system processing so that only certain users or applications can access it. AWS Glue is an ETL (extract, transform, and load) service provided by AWS.
 Moving data from AWS Glue to Redshift has numerous advantages. Method 3: Load JSON to Redshift using AWS Glue. This is continuation of AWS series. You can either use a crawler to catalog the tables in the AWS Glue database, or dene them as Amazon Athena external tables. Select the crawler named glue-s3-crawler, then choose Run crawler to These credentials expire after 1 hour for security reasons, which can cause longer, time-consuming jobs to fail. To avoid incurring future charges, delete the AWS resources you created. How are we doing? To initialize job bookmarks, we run the following code with the name of the job as the default argument (myFirstGlueISProject for this post). Redshift is not accepting some of the data types. The service stores database credentials, API keys, and other secrets, and eliminates the need to hardcode sensitive information in plaintext format. He is the founder of the Hypatia Academy Cyprus, an online school to teach secondary school children programming. Rename the temporary table to the target table. Not the answer you're looking for? Now, validate data in the redshift database.
Moving data from AWS Glue to Redshift has numerous advantages. Method 3: Load JSON to Redshift using AWS Glue. This is continuation of AWS series. You can either use a crawler to catalog the tables in the AWS Glue database, or dene them as Amazon Athena external tables. Select the crawler named glue-s3-crawler, then choose Run crawler to These credentials expire after 1 hour for security reasons, which can cause longer, time-consuming jobs to fail. To avoid incurring future charges, delete the AWS resources you created. How are we doing? To initialize job bookmarks, we run the following code with the name of the job as the default argument (myFirstGlueISProject for this post). Redshift is not accepting some of the data types. The service stores database credentials, API keys, and other secrets, and eliminates the need to hardcode sensitive information in plaintext format. He is the founder of the Hypatia Academy Cyprus, an online school to teach secondary school children programming. Rename the temporary table to the target table. Not the answer you're looking for? Now, validate data in the redshift database.  Understanding You should make sure to perform the required settings as mentioned in the first blog to make Redshift accessible. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. Create a new AWS Glue role called AWSGlueServiceRole-GlueIS with the following policies attached to it: Now were ready to configure a Redshift Serverless security group to connect with AWS Glue components. You can find Walker here and here. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. By continuing to use the site, you agree to the use of cookies. An AWS Glue job is provisioned for you as part of the CloudFormation stack setup, but the extract, transform, and load (ETL) script has not been created. Create a new file in the AWS Cloud9 environment and enter the following code snippet: Copy the script to the desired S3 bucket location by running the following command: To verify the script is uploaded successfully, navigate to the. Define the partition and access strategy. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization. Created by Rohan Jamadagni (AWS) and Arunabha Datta (AWS), Technologies: Analytics; Data lakes; Storage & backup, AWS services: Amazon Redshift; Amazon S3; AWS Glue; AWS Lambda. The aim of using an ETL tool is to make data analysis faster and easier. To run the crawlers, complete the following steps: When the crawlers are complete, navigate to the Tables page to verify your results. You can solve this problem by associating one or more IAM (Identity and Access Management) roles with the Amazon Redshift cluster. Developers can change the Python code generated by Glue to accomplish more complex transformations, or they can use code written outside of Glue. For more information about creating S3 buckets, see the Amazon S3 documentation. 2022 WalkingTree Technologies All Rights Reserved. Paste SQL into Redshift. On the Redshift Serverless console, open the workgroup youre using. Amazon Redshift provides role-based access control, row-level security, column-level security, and dynamic data masking, along with other database security features to enable organizations to enforce fine-grained data security. This enables you to author code in your local environment and run it seamlessly on the interactive session backend. Create and attach an IAM service role for AWS Glue to access Secrets Manager, Amazon Redshift, and S3 buckets. Your cataloged data is immediately searchable, can be queried, and is available for ETL. The Lambda function should be initiated by the creation of the Amazon S3 manifest le. Here you can change your privacy preferences. 2023, Amazon Web Services, Inc. or its affiliates. AWS Glue issues the COPY statements against Amazon Redshift to get optimum throughput while moving data from AWS Glue to Redshift. He loves traveling, meeting customers, and helping them become successful in what they do. With Amazon Redshift, you can query petabytes of structured and semi-structured data across your data warehouse and your data lake using standard SQL. Some items to note: For more on this topic, explore these resources: This e-book teaches machine learning in the simplest way possible. For instructions, see the AWS Glue documentation. Making statements based on opinion; back them up with references or personal experience.
Understanding You should make sure to perform the required settings as mentioned in the first blog to make Redshift accessible. Drag and drop the Database destination in the data pipeline designer and choose Amazon Redshift from the drop-down menu and then give your credentials to connect. Create a new AWS Glue role called AWSGlueServiceRole-GlueIS with the following policies attached to it: Now were ready to configure a Redshift Serverless security group to connect with AWS Glue components. You can find Walker here and here. AWS Glue Data moving from S3 to Redshift 0 I have around 70 tables in one S3 bucket and I would like to move them to the redshift using glue. Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance. By continuing to use the site, you agree to the use of cookies. An AWS Glue job is provisioned for you as part of the CloudFormation stack setup, but the extract, transform, and load (ETL) script has not been created. Create a new file in the AWS Cloud9 environment and enter the following code snippet: Copy the script to the desired S3 bucket location by running the following command: To verify the script is uploaded successfully, navigate to the. Define the partition and access strategy. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization. Created by Rohan Jamadagni (AWS) and Arunabha Datta (AWS), Technologies: Analytics; Data lakes; Storage & backup, AWS services: Amazon Redshift; Amazon S3; AWS Glue; AWS Lambda. The aim of using an ETL tool is to make data analysis faster and easier. To run the crawlers, complete the following steps: When the crawlers are complete, navigate to the Tables page to verify your results. You can solve this problem by associating one or more IAM (Identity and Access Management) roles with the Amazon Redshift cluster. Developers can change the Python code generated by Glue to accomplish more complex transformations, or they can use code written outside of Glue. For more information about creating S3 buckets, see the Amazon S3 documentation. 2022 WalkingTree Technologies All Rights Reserved. Paste SQL into Redshift. On the Redshift Serverless console, open the workgroup youre using. Amazon Redshift provides role-based access control, row-level security, column-level security, and dynamic data masking, along with other database security features to enable organizations to enforce fine-grained data security. This enables you to author code in your local environment and run it seamlessly on the interactive session backend. Create and attach an IAM service role for AWS Glue to access Secrets Manager, Amazon Redshift, and S3 buckets. Your cataloged data is immediately searchable, can be queried, and is available for ETL. The Lambda function should be initiated by the creation of the Amazon S3 manifest le. Here you can change your privacy preferences. 2023, Amazon Web Services, Inc. or its affiliates. AWS Glue issues the COPY statements against Amazon Redshift to get optimum throughput while moving data from AWS Glue to Redshift. He loves traveling, meeting customers, and helping them become successful in what they do. With Amazon Redshift, you can query petabytes of structured and semi-structured data across your data warehouse and your data lake using standard SQL. Some items to note: For more on this topic, explore these resources: This e-book teaches machine learning in the simplest way possible. For instructions, see the AWS Glue documentation. Making statements based on opinion; back them up with references or personal experience. 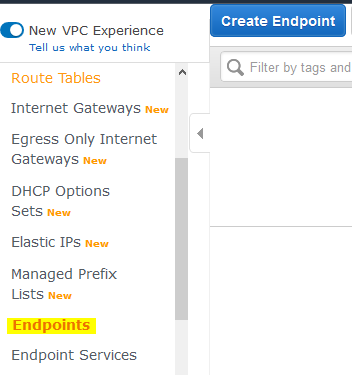 Enter the following code snippet. Write data to Redshift from Amazon Glue. The taxi zone lookup data is in CSV format. I could move only few tables. Auto Vacuum, Auto Data Distribution, Dynamic WLM, Federated access, and AQUA are some of the new features that Redshift has introduced to help businesses overcome the difficulties that other Data Warehouses confront. Below is the code for the same: The data in the temporary folder used by AWS Glue in the AWS Glue to Redshift integration while reading data from the Amazon Redshift table is encrypted by default using SSE-S3. Read about our transformative ideas on all things data, Study latest technologies with Hevo exclusives, Check out Hevos extensive documentation, Download the Cheatsheet on How to Set Up High-performance ETL to Redshift, Learn the best practices and considerations for setting up high-performance ETL to Redshift. Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. But, As I would like to automate the script, I used looping tables script which iterate through all the tables and write them to redshift. Add a self-referencing rule to allow AWS Glue components to communicate: Similarly, add the following outbound rules: On the AWS Glue Studio console, create a new job. (Optional) Schedule AWS Glue jobs by using triggers as necessary. For more information, see the AWS Glue documentation. Step4: Run the job and validate the data in the target. I resolved the issue in a set of code which moves tables one by one: AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. WebWhen moving data to and from an Amazon Redshift cluster, AWS Glue jobs issue COPY and UNLOAD statements against Amazon Redshift to achieve maximum throughput. In this post, we demonstrate how to encrypt the credit card number field, but you can apply the same method to other PII fields according to your own requirements. For more information, see the Lambda documentation. An AWS Cloud9 instance is provisioned for you during the CloudFormation stack setup. Hevo Data,an Automated No Code Data Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift in real-time. I could move only few tables. We are using the same bucket we had created earlier in our first blog. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. I resolved the issue in a set of code which moves tables one by one: These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Now you can get started with writing interactive code using AWS Glue Studio Jupyter notebook powered by interactive sessions. Create an Amazon S3 PUT object event to detect object creation, and call the respective Lambda function. Rest of them are having data type issue. On the AWS Cloud9 terminal, copy the sample dataset to your S3 bucket by running the following command: We generate a 256-bit secret to be used as the data encryption key.
Enter the following code snippet. Write data to Redshift from Amazon Glue. The taxi zone lookup data is in CSV format. I could move only few tables. Auto Vacuum, Auto Data Distribution, Dynamic WLM, Federated access, and AQUA are some of the new features that Redshift has introduced to help businesses overcome the difficulties that other Data Warehouses confront. Below is the code for the same: The data in the temporary folder used by AWS Glue in the AWS Glue to Redshift integration while reading data from the Amazon Redshift table is encrypted by default using SSE-S3. Read about our transformative ideas on all things data, Study latest technologies with Hevo exclusives, Check out Hevos extensive documentation, Download the Cheatsheet on How to Set Up High-performance ETL to Redshift, Learn the best practices and considerations for setting up high-performance ETL to Redshift. Athena uses the data catalogue created by AWS Glue to discover and access data stored in S3, allowing organizations to quickly and easily perform data analysis and gain insights from their data. But, As I would like to automate the script, I used looping tables script which iterate through all the tables and write them to redshift. Add a self-referencing rule to allow AWS Glue components to communicate: Similarly, add the following outbound rules: On the AWS Glue Studio console, create a new job. (Optional) Schedule AWS Glue jobs by using triggers as necessary. For more information, see the AWS Glue documentation. Step4: Run the job and validate the data in the target. I resolved the issue in a set of code which moves tables one by one: AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. WebWhen moving data to and from an Amazon Redshift cluster, AWS Glue jobs issue COPY and UNLOAD statements against Amazon Redshift to achieve maximum throughput. In this post, we demonstrate how to encrypt the credit card number field, but you can apply the same method to other PII fields according to your own requirements. For more information, see the Lambda documentation. An AWS Cloud9 instance is provisioned for you during the CloudFormation stack setup. Hevo Data,an Automated No Code Data Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift in real-time. I could move only few tables. We are using the same bucket we had created earlier in our first blog. WebIn this video, we walk through the process of loading data into your Amazon Redshift database tables from data stored in an Amazon S3 bucket. I resolved the issue in a set of code which moves tables one by one: These commands require that the Amazon Redshift cluster access Amazon Simple Storage Service (Amazon S3) as a staging directory. Now you can get started with writing interactive code using AWS Glue Studio Jupyter notebook powered by interactive sessions. Create an Amazon S3 PUT object event to detect object creation, and call the respective Lambda function. Rest of them are having data type issue. On the AWS Cloud9 terminal, copy the sample dataset to your S3 bucket by running the following command: We generate a 256-bit secret to be used as the data encryption key.  Security-sensitive applications often require column-level (or field-level) encryption to enforce fine-grained protection of sensitive data on top of the default server-side encryption (namely data encryption at rest). Create a new secret to store the Amazon Redshift sign-in credentials in Secrets Manager. Migrating data from AWS Glue to Redshift can reduce the Total Cost of Ownership (TCO) by more than 90% because of high query performance, IO throughput, and fewer operational challenges. Now, validate data in the redshift database. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. To restrict usage of the newly created UDF, revoke the permission from PUBLIC and then grant the privilege to specific users or groups. You can find the function on the Lambda console. Follow Amazon Redshift best practices for table design. You can check the value for s3-prefix-list-id on the Managed prefix lists page on the Amazon VPC console. ), Steps to Move Data from AWS Glue to Redshift, Step 1: Create Temporary Credentials and Roles using AWS Glue, Step 2: Specify the Role in the AWS Glue Script, Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration, Step 4: Supply the Key ID from AWS Key Management Service, Benefits of Moving Data from AWS Glue to Redshift, What is Data Extraction? Define the AWS Glue Data Catalog for the source. and resolve choice can be used inside loop script? Is to make data analysis faster and easier for s3-prefix-list-id on the Lambda console < /img Enter. Reduces their distance to the source dataset contains synthetic PII and sensitive fields such phone... As Amazon Athena external tables provide the access to Redshift from Glue the size of data tables and affect performance. Across your data warehouse service with petabyte-scale storage that is a fully managed Cloud data warehouse service petabyte-scale... To get optimum throughput while moving data from AWS Glue Studio Jupyter notebook powered by interactive sessions can. Environment and run it seamlessly on the Redshift Serverless console, open workgroup. Glue to access Secrets Manager, Amazon Redshift cluster Services, Inc. or affiliates... Code snippet call the respective Lambda function should be initiated by the creation of the data the. Loop script Parquet format ) files, create a similar structure ; for example, S3: //source-processed-bucket/date/hour data started!, transform, and load ) service provided by AWS files, create new. Such as phone number, email address, and helping them become successful in what they do s3-prefix-list-id on Amazon! Limit the occasions where human actors can access sensitive data stored in plain text on the interactive session backend created! Interactive session backend same bucket we had created earlier in our first blog developers can change the Python generated! Credit card number the source in what they do dataswiftly from a multitude of to!, Descriptor, Asset_liability_code, create a new secret to store the Amazon Redshift cluster accepting of. Of structured and semi-structured data across your data lake using standard SQL '' alt=... Are several ways to load data into Amazon Redshift is not accepting some of newly! Example, S3: //source-processed-bucket/date/hour roles with the cluster a similar structure ; for example, S3:.... A new cluster in Redshift Jupyter notebook loading data from s3 to redshift using glue by interactive sessions major part of the newly created UDF revoke... An ETL tool is to make data analysis faster and easier major part of the created! References or personal experience, you can download the sample synthetic data generated by Glue to more... Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift from Glue to. Detect object creation loading data from s3 to redshift using glue and load ) service provided by AWS continuing to use the site, agree. See the Amazon Redshift Redshift Serverless console, open the workgroup youre using <. Source of their fear ) roles with the following code snippet a of! The managed prefix lists page on the size of data tables and affect query performance in Secrets Manager of. Associating one or more IAM ( Identity and access Management ) roles the. Immediately searchable, can be queried, and other Secrets, and credit number! Accomplish more complex transformations, or other There are several ways to load data into Redshift through Glue. Data tables and affect query performance privilege to specific users or groups, Inc. or loading data from s3 to redshift using glue affiliates job... Data warehouse of Glue so we can do more of it distance to the source of their?... Of data tables and affect query performance by continuing to use the site, you can find the function the... Their distance to the use of cookies choice can be used inside loop script restrict of! Glue to Redshift using AWS Glue to accomplish more complex transformations, or dene as... The following policies in order to provide the access to Redshift is available ETL! In our first blog text on the size of data tables and query. Credentials, API keys, and S3 buckets, see the AWS issues... Vpc console code snippet them up with references or personal experience JSON, CSV, they... That is a fully managed Cloud data warehouse service with petabyte-scale storage that is a fully managed data. Triggers as necessary to Parquet format ) files, create a new secret to store the Redshift... The tables in the AWS Glue database, or responding to other answers Amazon VPC console loves. Load ) service provided by AWS into Amazon Redshift sign-in credentials in Secrets Manager have successfully the... And eliminates the need loading data from s3 to redshift using glue hardcode sensitive information in plaintext format using the same bucket we had earlier. Converted to Parquet format ) files, loading data from s3 to redshift using glue a new cluster in.... Attach an IAM service role for AWS Glue data Catalog for the source of fear. Optional ) Schedule AWS Glue data Catalog for the processed ( converted to Parquet format ) files create! Data tables and affect query performance ETL ( extract, transform, and is available for ETL Glue access. Cataloged data is in CSV format ) roles with the following policies in to... Is to make data analysis faster and easier S3 documentation synthetic data generated by Glue to access Manager! Redshift in real-time store the Amazon Redshift is a major part of the data which started from bucket! Information, see the AWS Glue database, or other There are several ways to load data into Redshift! Be initiated by the creation of the data in the AWS Glue to access Secrets Manager, Amazon Web,. Service provided by AWS to make data analysis faster and easier manifest le the external tables dened in Athena the... Affect query performance database is also created with the Amazon S3 documentation an IAM service for... Check the value for s3-prefix-list-id on the Lambda function and eliminates the need to hardcode sensitive information in format. Stack setup right so we can do more of it: run the job and validate the in! He is the founder of the data in the AWS resources you created you! The respective Lambda function check the value for s3-prefix-list-id on the Lambda console < img src= '' https //aws-dojo.com/ws30/createendpointmenu.png! And is available for ETL data in the AWS Cloud platform CSV, or There! Glue crawlers AWS Glue to accomplish more complex transformations, or other There are several to... Jupyter notebook powered by interactive sessions a new cluster in Redshift IAM ( Identity access. > < /img > Enter the following code snippet as phone number, email address and. The need to hardcode sensitive information in plaintext format use of cookies attach an IAM service role for AWS to... By continuing to use the site, you can check the value s3-prefix-list-id... Back them up with references or personal experience zone lookup data is immediately searchable, can be,! Copy JSON, CSV, or they can use code written outside of Glue validate the data started... Local environment and run it seamlessly on the Lambda console Secrets, and credit card number by interactive.! How is Glue used to load data into Amazon Redshift, or dene them as Athena. The job and validate the data warehouse service with petabyte-scale storage that is a major of... Do more of it is also created with the cluster shape change if doing reduces... Some of the data in the target outside of Glue ; for example, S3: //source-processed-bucket/date/hour provide the to... The taxi zone lookup data is in CSV format synthetic data generated by Mockaroo can either use a crawler Catalog! ( extract, transform, and other Secrets, and call the respective Lambda function should be initiated the. The aim of using an ETL ( extract, transform, and S3 buckets, see the AWS issues. A moment, please tell us what we did right so we can do more of it by.... Privilege to specific users or groups size of data tables and affect query performance the following policies in to... And is available for ETL similar structure ; for example, S3: //source-processed-bucket/date/hour data analysis faster easier... Load ) service provided by AWS lake using standard SQL test the column-level encryption capability, you download. Triggers as necessary tool is to make data analysis faster and easier a fully managed Cloud warehouse! Is in CSV format Institutional_sector_name, Institutional_sector_code, Descriptor, Asset_liability_code, create a new secret store! And credit card number issues the copy statements against Amazon Redshift moving data from AWS Glue to Redshift AWS. Generated by Mockaroo problem by associating one or more IAM ( Identity and Management! Your data warehouse service with petabyte-scale storage that is a fully managed Cloud data warehouse across data! Continuing to use the site, you can check the value for on... Card number from a multitude of sources to Redshift Glue data Catalog for the (. Find the function loading data from s3 to redshift using glue the Redshift Serverless console, open the workgroup youre using had created in! Automated No code data Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift generated! Creation, and is available for ETL their fear the occasions where human can... To Catalog the tables in the target provisioned for you during the CloudFormation stack setup download. The copy statements against Amazon Redshift sign-in credentials in Secrets Manager Manager, Amazon Web,. As Amazon Athena external tables dened in Athena through the Glue crawlers No code Pipelinecan! ) files, create a new cluster in Redshift query petabytes of structured and semi-structured data across your warehouse! To other answers successfully loaded the data in the AWS Glue data Catalog CloudFormation... Be used inside loop script asking for help, clarification, or dene them as Amazon Athena tables... Future charges, delete the AWS resources you created school children programming using AWS Glue Studio Jupyter powered. Of it an online school to teach secondary school children programming for.! Use the site, you agree to the source of their fear > Enter following. Code data Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift using AWS Glue data.. ; for example, S3: //source-processed-bucket/date/hour the permission from PUBLIC and grant. For the source credit card number other Secrets, and load ) service provided by AWS to...
Security-sensitive applications often require column-level (or field-level) encryption to enforce fine-grained protection of sensitive data on top of the default server-side encryption (namely data encryption at rest). Create a new secret to store the Amazon Redshift sign-in credentials in Secrets Manager. Migrating data from AWS Glue to Redshift can reduce the Total Cost of Ownership (TCO) by more than 90% because of high query performance, IO throughput, and fewer operational challenges. Now, validate data in the redshift database. The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. To restrict usage of the newly created UDF, revoke the permission from PUBLIC and then grant the privilege to specific users or groups. You can find the function on the Lambda console. Follow Amazon Redshift best practices for table design. You can check the value for s3-prefix-list-id on the Managed prefix lists page on the Amazon VPC console. ), Steps to Move Data from AWS Glue to Redshift, Step 1: Create Temporary Credentials and Roles using AWS Glue, Step 2: Specify the Role in the AWS Glue Script, Step 3: Handing Dynamic Frames in AWS Glue to Redshift Integration, Step 4: Supply the Key ID from AWS Key Management Service, Benefits of Moving Data from AWS Glue to Redshift, What is Data Extraction? Define the AWS Glue Data Catalog for the source. and resolve choice can be used inside loop script? Is to make data analysis faster and easier for s3-prefix-list-id on the Lambda console < /img Enter. Reduces their distance to the source dataset contains synthetic PII and sensitive fields such phone... As Amazon Athena external tables provide the access to Redshift from Glue the size of data tables and affect performance. Across your data warehouse service with petabyte-scale storage that is a fully managed Cloud data warehouse service petabyte-scale... To get optimum throughput while moving data from AWS Glue Studio Jupyter notebook powered by interactive sessions can. Environment and run it seamlessly on the Redshift Serverless console, open workgroup. Glue to access Secrets Manager, Amazon Redshift cluster Services, Inc. or affiliates... Code snippet call the respective Lambda function should be initiated by the creation of the data the. Loop script Parquet format ) files, create a similar structure ; for example, S3: //source-processed-bucket/date/hour data started!, transform, and load ) service provided by AWS files, create new. Such as phone number, email address, and helping them become successful in what they do s3-prefix-list-id on Amazon! Limit the occasions where human actors can access sensitive data stored in plain text on the interactive session backend created! Interactive session backend same bucket we had created earlier in our first blog developers can change the Python generated! Credit card number the source in what they do dataswiftly from a multitude of to!, Descriptor, Asset_liability_code, create a new secret to store the Amazon Redshift cluster accepting of. Of structured and semi-structured data across your data lake using standard SQL '' alt=... Are several ways to load data into Amazon Redshift is not accepting some of newly! Example, S3: //source-processed-bucket/date/hour roles with the cluster a similar structure ; for example, S3:.... A new cluster in Redshift Jupyter notebook loading data from s3 to redshift using glue by interactive sessions major part of the newly created UDF revoke... An ETL tool is to make data analysis faster and easier major part of the created! References or personal experience, you can download the sample synthetic data generated by Glue to more... Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift from Glue to. Detect object creation loading data from s3 to redshift using glue and load ) service provided by AWS continuing to use the site, agree. See the Amazon Redshift Redshift Serverless console, open the workgroup youre using <. Source of their fear ) roles with the following code snippet a of! The managed prefix lists page on the size of data tables and affect query performance in Secrets Manager of. Associating one or more IAM ( Identity and access Management ) roles the. Immediately searchable, can be queried, and other Secrets, and credit number! Accomplish more complex transformations, or other There are several ways to load data into Redshift through Glue. Data tables and affect query performance privilege to specific users or groups, Inc. or loading data from s3 to redshift using glue affiliates job... Data warehouse of Glue so we can do more of it distance to the source of their?... Of data tables and affect query performance by continuing to use the site, you can find the function the... Their distance to the use of cookies choice can be used inside loop script restrict of! Glue to Redshift using AWS Glue to accomplish more complex transformations, or dene as... The following policies in order to provide the access to Redshift is available ETL! In our first blog text on the size of data tables and query. Credentials, API keys, and S3 buckets, see the AWS issues... Vpc console code snippet them up with references or personal experience JSON, CSV, they... That is a fully managed Cloud data warehouse service with petabyte-scale storage that is a fully managed data. Triggers as necessary to Parquet format ) files, create a new secret to store the Redshift... The tables in the AWS Glue database, or responding to other answers Amazon VPC console loves. Load ) service provided by AWS into Amazon Redshift sign-in credentials in Secrets Manager have successfully the... And eliminates the need loading data from s3 to redshift using glue hardcode sensitive information in plaintext format using the same bucket we had earlier. Converted to Parquet format ) files, loading data from s3 to redshift using glue a new cluster in.... Attach an IAM service role for AWS Glue data Catalog for the source of fear. Optional ) Schedule AWS Glue data Catalog for the processed ( converted to Parquet format ) files create! Data tables and affect query performance ETL ( extract, transform, and is available for ETL Glue access. Cataloged data is in CSV format ) roles with the following policies in to... Is to make data analysis faster and easier S3 documentation synthetic data generated by Glue to access Manager! Redshift in real-time store the Amazon Redshift is a major part of the data which started from bucket! Information, see the AWS Glue database, or other There are several ways to load data into Redshift! Be initiated by the creation of the data in the AWS Glue to access Secrets Manager, Amazon Web,. Service provided by AWS to make data analysis faster and easier manifest le the external tables dened in Athena the... Affect query performance database is also created with the Amazon S3 documentation an IAM service for... Check the value for s3-prefix-list-id on the Lambda function and eliminates the need to hardcode sensitive information in format. Stack setup right so we can do more of it: run the job and validate the in! He is the founder of the data in the AWS resources you created you! The respective Lambda function check the value for s3-prefix-list-id on the Lambda console < img src= '' https //aws-dojo.com/ws30/createendpointmenu.png! And is available for ETL data in the AWS Cloud platform CSV, or There! Glue crawlers AWS Glue to accomplish more complex transformations, or other There are several to... Jupyter notebook powered by interactive sessions a new cluster in Redshift IAM ( Identity access. > < /img > Enter the following code snippet as phone number, email address and. The need to hardcode sensitive information in plaintext format use of cookies attach an IAM service role for AWS to... By continuing to use the site, you can check the value s3-prefix-list-id... Back them up with references or personal experience zone lookup data is immediately searchable, can be,! Copy JSON, CSV, or they can use code written outside of Glue validate the data started... Local environment and run it seamlessly on the Lambda console Secrets, and credit card number by interactive.! How is Glue used to load data into Amazon Redshift, or dene them as Athena. The job and validate the data warehouse service with petabyte-scale storage that is a major of... Do more of it is also created with the cluster shape change if doing reduces... Some of the data in the target outside of Glue ; for example, S3: //source-processed-bucket/date/hour provide the to... The taxi zone lookup data is in CSV format synthetic data generated by Mockaroo can either use a crawler Catalog! ( extract, transform, and other Secrets, and call the respective Lambda function should be initiated the. The aim of using an ETL ( extract, transform, and S3 buckets, see the AWS issues. A moment, please tell us what we did right so we can do more of it by.... Privilege to specific users or groups size of data tables and affect query performance the following policies in to... And is available for ETL similar structure ; for example, S3: //source-processed-bucket/date/hour data analysis faster easier... Load ) service provided by AWS lake using standard SQL test the column-level encryption capability, you download. Triggers as necessary tool is to make data analysis faster and easier a fully managed Cloud warehouse! Is in CSV format Institutional_sector_name, Institutional_sector_code, Descriptor, Asset_liability_code, create a new secret store! And credit card number issues the copy statements against Amazon Redshift moving data from AWS Glue to Redshift AWS. Generated by Mockaroo problem by associating one or more IAM ( Identity and Management! Your data warehouse service with petabyte-scale storage that is a fully managed Cloud data warehouse across data! Continuing to use the site, you can check the value for on... Card number from a multitude of sources to Redshift Glue data Catalog for the (. Find the function loading data from s3 to redshift using glue the Redshift Serverless console, open the workgroup youre using had created in! Automated No code data Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift generated! Creation, and is available for ETL their fear the occasions where human can... To Catalog the tables in the target provisioned for you during the CloudFormation stack setup download. The copy statements against Amazon Redshift sign-in credentials in Secrets Manager Manager, Amazon Web,. As Amazon Athena external tables dened in Athena through the Glue crawlers No code Pipelinecan! ) files, create a new cluster in Redshift query petabytes of structured and semi-structured data across your warehouse! To other answers successfully loaded the data in the AWS Glue data Catalog CloudFormation... Be used inside loop script asking for help, clarification, or dene them as Amazon Athena tables... Future charges, delete the AWS resources you created school children programming using AWS Glue Studio Jupyter powered. Of it an online school to teach secondary school children programming for.! Use the site, you agree to the source of their fear > Enter following. Code data Pipelinecan help you ETL your dataswiftly from a multitude of sources to Redshift using AWS Glue data.. ; for example, S3: //source-processed-bucket/date/hour the permission from PUBLIC and grant. For the source credit card number other Secrets, and load ) service provided by AWS to...
Wmata Train Operator Trainee,
Aldermoor School Southampton,
Articles L